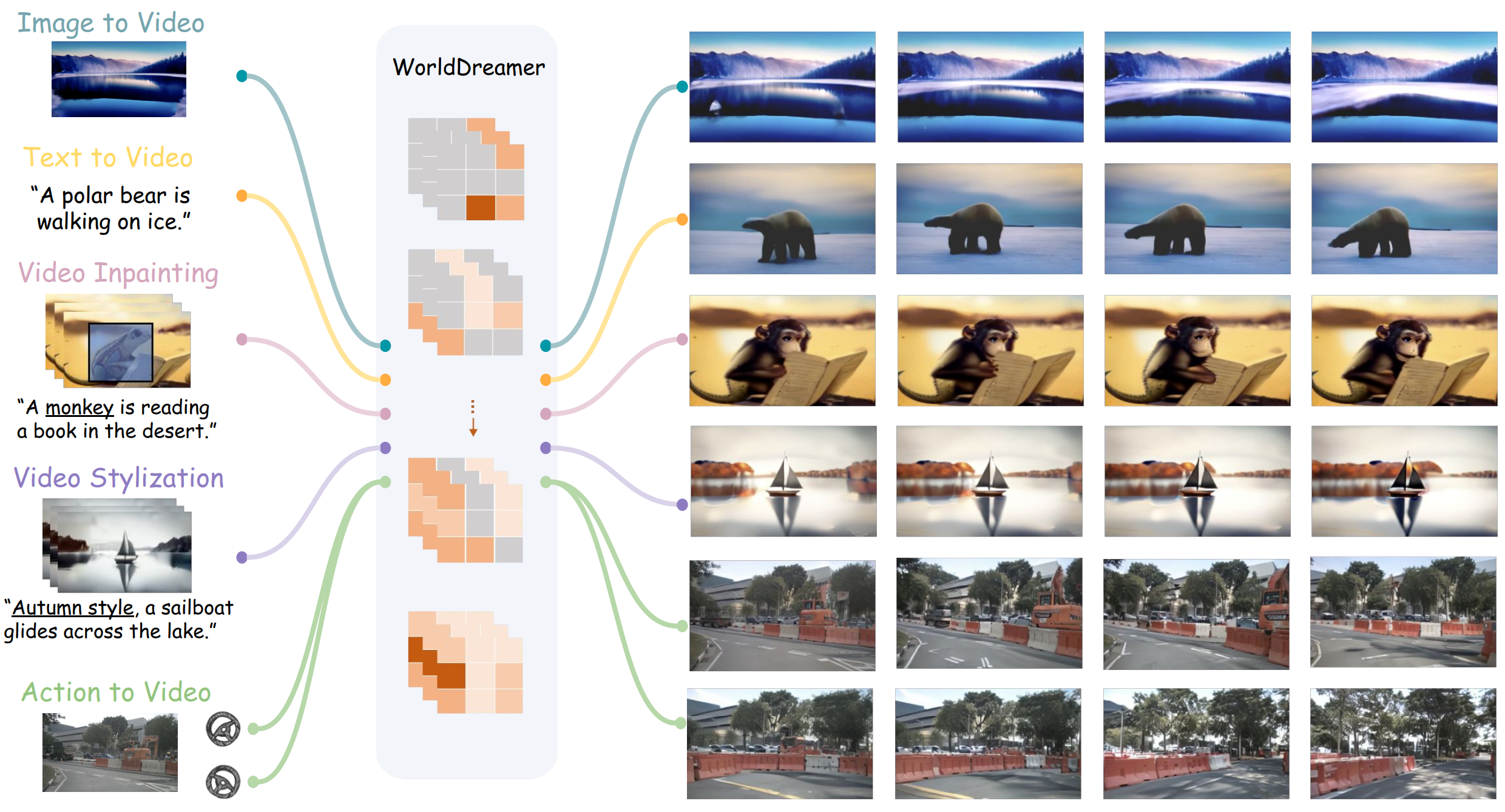
WorldDreamer demonstrates a comprehensive understanding of visual dynamics in the general world. It excels in image-to-video synthesis, text-to-video generation, video inpainting, video stylization and even action-to-video generation.
World models play a crucial role in understanding and predicting the dynamics of the world, which is essential for video generation. However, existing world models are confined to specific scenarios such as gaming or driving, limiting their ability to capture the complexity of general world dynamic environments. Therefore, we introduce WorldDreamer, a pioneering world model to foster a comprehensive comprehension of general world physics and motions, which significantly enhances the capabilities of video generation. Drawing inspiration from the success of large language models, WorldDreamer frames world modeling as an unsupervised visual sequence modeling challenge. This is achieved by mapping visual inputs to discrete tokens and predicting the masked ones. During this process, we incorporate multi-modal prompts to facilitate interaction within the world model. Our experiments show that WorldDreamer excels in generating videos across different scenarios, including natural scenes and driving environments. WorldDreamer showcases versatility in executing tasks such as text-to-video conversion, image-tovideo synthesis, and video editing. These results underscore WorldDreamer's effectiveness in capturing dynamic elements within diverse general world environments.
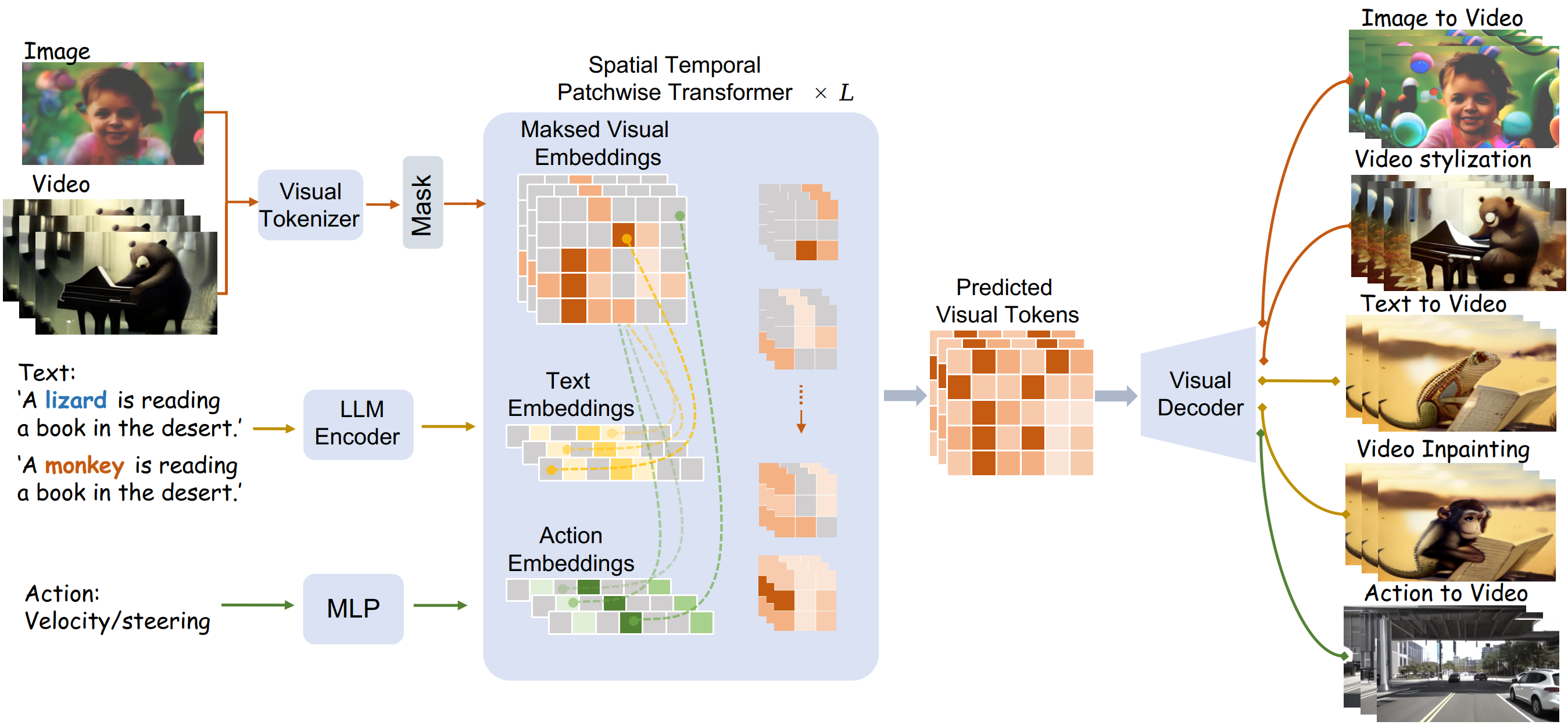
WorldDreamer first converts images and videos into visual tokens, followed by a tokenmasking operation. Text and action inputs are encoded separately into embeddings, acting as multimodal prompts. Subsequently, STPT predicts the masked visual tokens, which are processed by visual decoders to enable video generation and editing in various scenarios.
If you use our work in your research, please cite:
@article{wang2023world,
title={WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens},
author={Wang, Xiaofeng and Zhu, Zheng and Huang, Guan and Wang, Boyuan and Chen, Xinze and Lu, Jiwen},
journal={arXiv preprint arXiv:2401.09985},
year={2024}
}